DigitalOcean Gradient™ AI GPU Droplets Optimized for Inference: Increasing Throughput at Lower the Cost
By Jason Peng and Hemasumanth Rasineni
- Updated:
- 11 min read
Production-grade LLM inference demands more than just access to GPUs; it requires deep optimization across the entire serving stack, from quantization and attention kernels to memory management and parallelism strategies. Most teams deploying models like Llama 3.3 70B on vanilla configurations are leaving the majority of their hardware’s capability on the table: underutilized FLOPs, wasted memory bandwidth, and GPU hours spent waiting instead of computing.
To solve this, we built the Inference Optimized Image a fully pre-configured OS image available on DigitalOcean’s GPU Droplets — that layers speculative decoding, FP8 quantization, FlashAttention-3, paged attention, concurrent optimization, and prompt caching into a single deployable image. The result of our particular test: 143% higher throughput (2,000 vs. 823 tokens/second), 40.7% lower TTFT (187.9ms vs. 316.83ms), and a 75% reduction in cost per million tokens ($1.472 vs. $5.80) — all while running Llama 3.3 70B on 2 H100 GPUs instead of 4.
In this post, we walk through the optimization stack, the engineering reasoning behind each layer, and the benchmark methodology and our test results showing these gains.
Prefill, Decode, and Why Optimization is Multiplicative
As we covered in our LLM Inference Benchmarking post, inference works in two distinct phases with fundamentally different computation characteristics. The prefill phase processes the entire input prompt through the model’s forward pass self-attention, layer norms, feed-forward networks and is compute-bound, with high arithmetic intensity (FLOPs per byte transferred). The decode phase generates tokens one at a time, loading the full weight matrix and KV cache from HBM for each token, making it strictly memory-bandwidth-bound.
This distinction matters because each optimization in our stack targets a specific bottleneck. Speculative decoding attacks the sequential nature of decode. FP8 quantization reduces memory footprint and accelerates compute via higher-throughput Tensor Cores. FlashAttention-3 optimizes the prefill-heavy attention computation. Paged attention improves memory utilization under concurrent load. The gains are multiplicative each layer compounds on the others because they address orthogonal bottlenecks in the inference pipeline.
The Optimization Stack
Speculative Decoding
Standard autoregressive generation is inherently sequential: each token requires a full forward pass through the 70B model, and at decode time, that forward pass is dominated by memory bandwidth the GPU spends more time moving weights from HBM to compute cores than performing matrix multiplications.
Speculative decoding breaks this pattern with a small, fast draft model that proposes multiple candidate tokens in parallel. The full 70B target model then verifies these candidates in a single forward pass and because verification of N tokens costs roughly the same as generating 1, accepted speculations yield multiple tokens for the compute cost of one.
The engineering challenge is draft model selection: fast enough that overhead doesn’t eat the gains, accurate enough that proposals are frequently accepted. We tuned the draft-target pair specifically for the Llama 3.3 70B architecture, optimizing acceptance rates across our benchmark workload distributions. Speculative decoding is the single largest contributor to both the throughput improvement and TTFT reduction in our stack.
FP8 Quantization
Running Llama 3.3 70B at FP16 precision requires approximately 140GB of GPU memory for weights alone, nearly two H100s worth of HBM3 before allocating anything for KV cache, activations, or batch state. This is why vanilla deployments typically need 4 H100 GPUs.
FP8 quantization halves the memory footprint by representing weights in 8-bit floating point (E4M3), compressing the 70B model to ~70GB and making it feasible to serve on 2 H100 GPUs with TP=2. But the benefit goes beyond memory: H100 FP8 Tensor Cores deliver 2× the peak FLOPS compared to FP16 1,979 TFLOPS vs. 989 TFLOPS. Quantization doesn’t just let us fit the model on fewer GPUs; it makes each GPU compute faster on every forward pass.
The practical result: FP8 enables the 2×H100 configuration that underpins the 75% cost reduction of half the GPUs, each running faster.
Flash Attention-3 and Paged Attention
Attention computation scales quadratically with sequence length, making it a major bottleneck for longer prompts and generations. Two complementary optimizations address this.
FlashAttention-3 restructures attention to minimize HBM reads and writes. Instead of materializing the full N×N attention matrix in GPU memory, it tiles the computation so attention scores are computed and consumed in SRAM (fast on-chip memory) without ever writing the full matrix to HBM. On H100s, it also exploits the TMA (Tensor Memory Accelerator) unit to overlap data movement with computation, a capability unique to the Hopper architecture.
Paged attention tackles KV cache memory management. In vanilla setups, KV cache is pre-allocated contiguously per request, causing fragmentation short sequences hold reserved memory that longer sequences need. Paged attention borrows the virtual memory concept from operating systems, managing KV cache in fixed-size blocks allocated on demand. This dramatically improves memory utilization under variable-length concurrent workloads.
Together, these optimizations let us serve more concurrent requests within the same memory envelope, keeping throughput high and TTFT stable as concurrency scales from 1 to 16 users.
Concurrent Optimization
This is perhaps the least intuitive optimization in our stack, but it delivers some of the most dramatic gains for multi-model deployments.
Concurrent optimization means running multiple instances of the same model in parallel on the same hardware, rather than the typical vLLM approach of one model instance occupying all available GPUs. The insight is rooted in GPU utilization patterns: a single 70B model split across 8 GPUs using TP=8 often can’t fully saturate the memory bandwidth of all GPUs due to inter-GPU communication overhead. Every all_reduce and all_gather operation introduces latency that leaves compute units idle.
With 4 concurrent instances at TP=2 each, every GPU pair works independently, achieving better bandwidth utilization. There’s also a batch processing efficiency argument — with a single model, all requests funnel through one inference pipeline, creating a serialization bottleneck. With 4 concurrent models, you have 4 parallel processing pipelines, each building and processing batches independently.
The measured impact on 8×H100 GPUs:
| Model | Single Instance (tok/s) | 4 Concurrent (tok/s) | Measured Improvement |
|---|---|---|---|
| Llama 3.1 8B | 59,941 | 101,804 | +69.8% |
| Llama 3.3 70B | 11,927 | 22,948 | +92.4% |
| DeepSeek-R1-Distill 70B | 12,202 | 23,348 | +91.3% |
These gains come primarily from better hardware utilization, no model changes, no additional GPUs, just smarter resource allocation across the same silicon.
Prompt Caching
For applications where users send overlapping prompts, system prompts, few-shot examples, shared document context recomputing the KV cache for identical prefix tokens is pure waste. Prompt caching stores and reuses KV cache entries for previously computed prompt prefixes, eliminating redundant prefill computation on subsequent requests that share the same prefix.
In production workloads, it’s common for 50–80% of a prompt to consist of shared context (system instructions, tool definitions, reference documents). Prompt caching makes those shared tokens effectively free on subsequent requests, reducing both TTFT and per-request compute cost proportional to the overlap ratio.
Benchmark Methodology
We evaluated the Inference Optimized Image against a vanilla (non-optimized) baseline across three realistic use-case scenarios designed to stress different aspects of the inference pipeline:
| Scenario | Input Tokens | Output Tokens | Use Case |
|---|---|---|---|
| Standard Chat | 512 | 512 | Conversational AI, chatbots |
| Summarization | 1,024 | 512 | Document summarization, extraction |
| Long-form Generation | 2,048 | 1,024 | Content creation, detailed analysis |
Each scenario was tested at concurrency levels of 1, 2, 4, 8, and 16 simultaneous users. All benchmarks used Llama 3.3 70B as the target model with the vLLM inference engine as the serving backend. The optimized configuration runs on 2×H100 GPUs (TP=2), while the baseline uses 4×H100 GPUs (TP=4) with no optimization applied. Numbers reported below are averages across all scenarios and concurrency levels.
Test Results
Throughput: 143% Improvement over Baseline
The optimized image achieves 2,000 tokens/second on 2×H100 GPUs, compared to the baseline’s 823 tokens/second on 4×H100 GPUs.
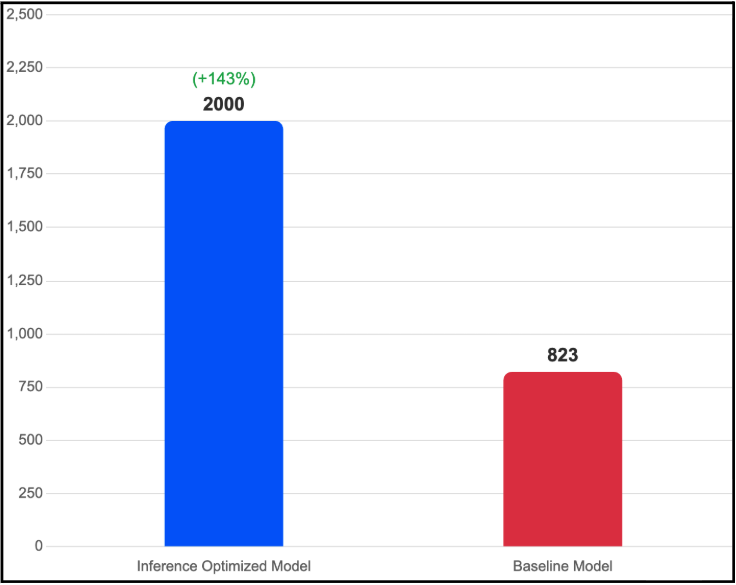
Figure 1: Output throughput comparison Inference Optimized Image (2×H100, TP=2) vs. Baseline (4×H100, TP=4). The optimized configuration achieves 143% higher throughput while using half the GPU resources.
This isn’t just faster per-GPU, it’s faster in absolute terms while using half the hardware. The compounding effect of speculative decoding (more tokens per forward pass), FP8 quantization (faster forward passes via FP8 Tensor Cores), and the reduced TP=2 communication overhead (less inter-GPU synchronization) all contribute to this result.
It’s worth noting that the throughput advantage is most pronounced at lower concurrency levels. As we detailed in our benchmarking methodology post, there’s always a Pareto frontier tension between throughput and concurrency at very high concurrency (32+), the memory constraints of the TP=2 configuration begin to limit the gains. For most production workloads operating in the 1–16 concurrency range, the 143% improvement holds.
Time-to-First-Token: 40.7% Reduction Compared to Baseline
The optimized image delivers a TTFT of 187.9ms, compared to the baseline’s 316.83ms.
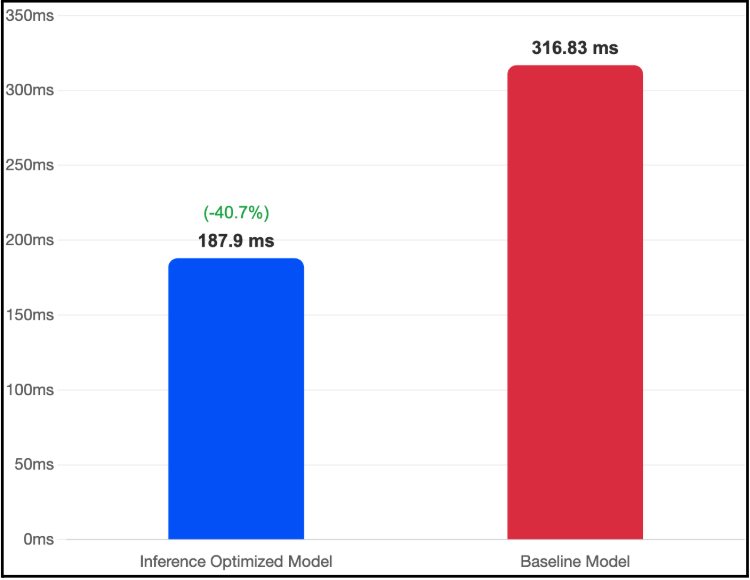
Figure 2: Time-to-First-Token comparison Inference Optimized Image vs. Baseline. At 187.9ms, the optimized configuration sits well below the 200ms threshold typically associated with perceived “instantaneous” response in interactive applications.
For interactive applications chatbots, coding assistants, real-time agents TTFT is what users feel. The improvement comes primarily from speculative decoding (the draft model generates the first token faster than the full 70B model) and FlashAttention-3 (faster prefill computation for the input prompt). At 187.9ms, we’re comfortably below the 200ms mark that UX research consistently identifies as the boundary of perceived immediate response.
Cost Efficiency: 75% Reduction Compared to Baseline
The optimized image delivers inference at $1.472 per million tokens, compared to the baseline’s $5.80 per million tokens.
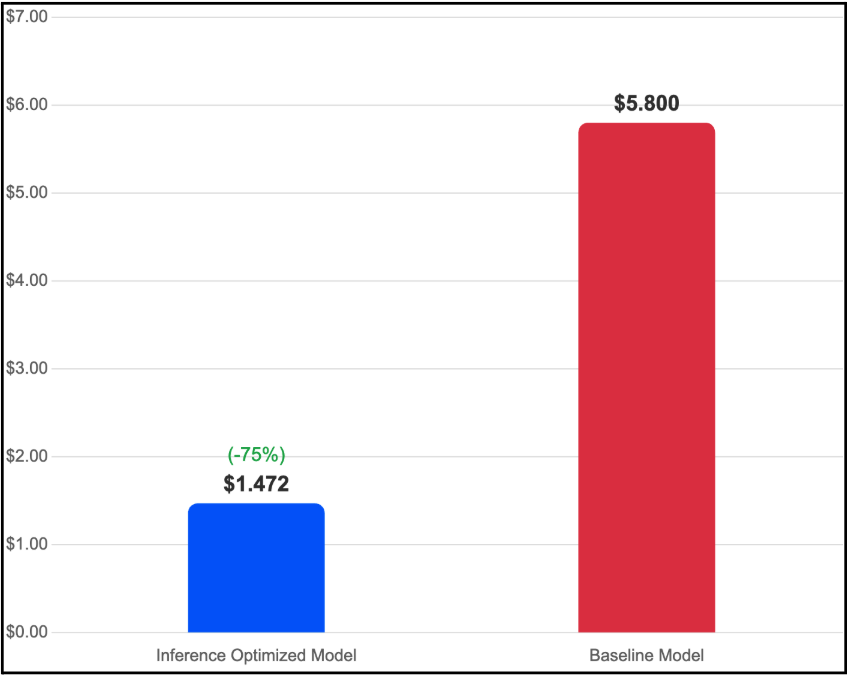
Figure 3: Cost efficiency comparison measured in dollars per million tokens. The optimized image achieves a 75% reduction in per-token cost through the combination of halved GPU requirements and higher throughput per GPU.
The cost reduction is multiplicative: the optimized image runs on 2 H100 GPUs instead of 4, immediately halving hourly infrastructure cost. Combined with 143% higher throughput each dollar of GPU time produces dramatically more output; the per-token cost drops by 75%. For teams running inference at scale, a workload costing $10,000/month on a vanilla deployment could potentially drop to approximately $2,500/month on the optimized image, with better latency and throughput based on our test results (although actual results in Production may vary depending on relevant implementation details).
Throughput vs. Concurrency
The aggregate numbers above tell part of the story. The concurrency-level breakdown reveals how the optimized configuration scales under increasing load.
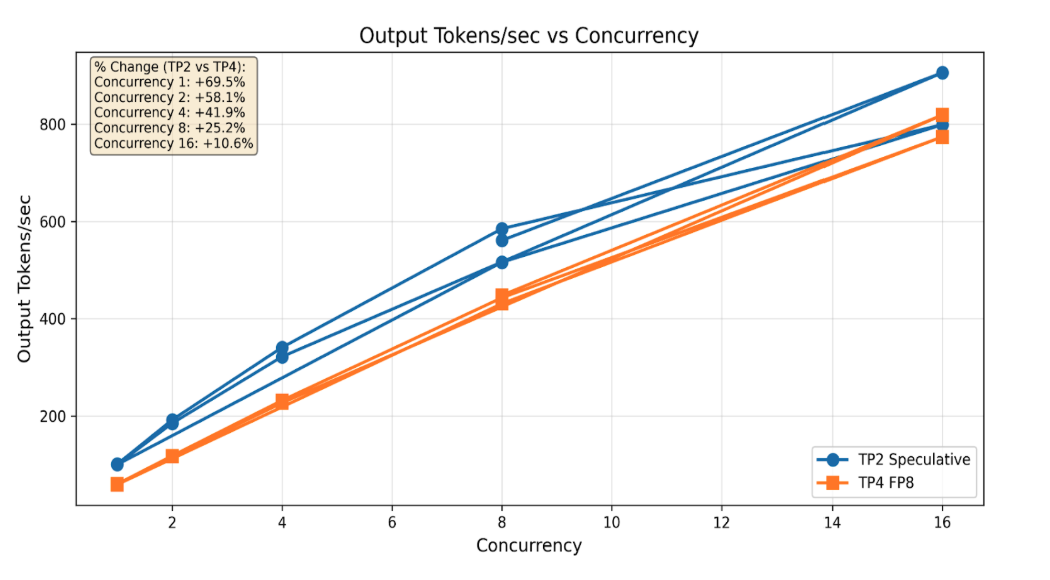
Figure 4: Output tokens/second across concurrency levels (1–16) for the Inference Optimized Image (TP=2, speculative decoding) vs. Baseline (TP=4, FP8 only). The optimized configuration maintains its throughput advantage across all tested concurrency levels, with the largest relative gains at lower concurrency.
At concurrency 1, the optimized configuration shows a +69.5% improvement. This advantage holds through concurrency 2 (+59.1%), 4 (+41.8%), 8 (+25.3%), and 16 (+10.6%). The converging curves at higher concurrency reflect the memory constraints inherent in the TP=2 configuration; at extreme concurrency, the larger KV cache memory available in a TP=4 setup begins to narrow the gap.
Cost per Million Tokens vs. Concurrency
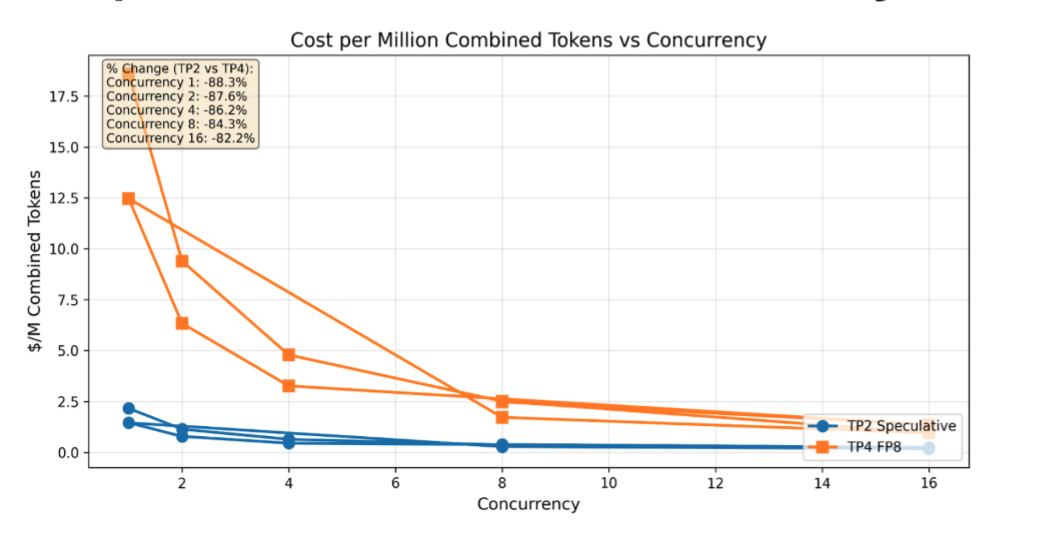
Figure 5: Cost per million combined tokens across concurrency levels. The optimized configuration delivers substantial cost savings at all concurrency levels, with the largest advantage at low-to-moderate concurrency where most production workloads operate. At concurrency 1, the cost reduction exceeds 88%; at concurrency 16, it remains above 42%.
This chart is particularly relevant for capacity planning. Most production inference workloads don’t sustain concurrency 16+ continuously they operate in the 1–8 range with occasional bursts. In this sweet spot, the Inference Optimized Image delivers its most dramatic cost-per-token advantage.
From 4 GPUs to 2: The Infrastructure Efficiency Story
One of the most compelling outcomes of this work is what it means for infrastructure planning. Running Llama 3.3 70B in production has traditionally required a minimum of 4 H100 GPUs — at FP16 precision, the model simply doesn’t fit on fewer cards with room for KV cache and concurrent request batching.
The optimized image changes this equation fundamentally. FP8 quantization compresses the model to fit within 2×H100 GPUs. Speculative decoding and FlashAttention-3 ensure the 2-GPU configuration doesn’t just fit the model but outperforms the unoptimized 4-GPU setup. Paged attention handles KV cache management efficiently at high concurrency so the 2-GPU deployment doesn’t buckle under production load.
The cascading effects on infrastructure economics appear to be significant: fewer GPU nodes, less inter-GPU communication overhead (NVLink between 2 GPUs is simpler than mesh communication across 4), lower power consumption, and less operational complexity. The 75% cost-per-token reduction seemingly captures the direct compute savings, but total cost of ownership improvement could be larger when factoring in these second-order effects.
The flexibility extends across GPU tiers. While these headline benchmarks focus on H100 GPUs, the Inference Optimized Image supports NVIDIA L40S and RTX 6000 ADA as well. The same optimization stack applies across GPU architectures, making production-grade inference accessible across a range of price points from flagship H100 for maximum throughput to cost-effective L40S for budget-conscious deployments.
What This Means for Inference at Scale
Building and benchmarking this optimized image revealed several patterns about where GPU inference is heading patterns that extend beyond any single model or hardware configuration.
Optimization is multiplicative, not additive. The 143% throughput gain isn’t the result of one technique. It’s the product of speculative decoding, FP8, FlashAttention-3, paged attention, concurrent optimization, and prompt caching each contributing improvements that compound because they address orthogonal bottlenecks. Optimizing only one layer captures a fraction of available performance. The full stack matters.
Hardware efficiency is fundamentally a software problem. The same physical H100 GPUs deliver wildly different performance depending on how they’re configured. Our benchmarks show that vanilla configurations utilize a fraction of available throughput capacity. The Inference Optimized Image closes this gap with software alone no custom silicon, no hardware modifications, just careful tuning of the serving stack. As we noted in our benchmarking methodology post, understanding the speed-of-light frontier for your specific hardware is the essential first step.
Fewer GPUs can mean better performance. Running Llama 3.3 70B on 2 GPUs with TP=2 and speculative decoding outperformed 4 GPUs with TP=4 and no optimization. The reason: TP=4 introduces more inter-GPU communication overhead via all_reduce operations, and without speculative decoding, each forward pass generates only one token regardless of GPU count. Smarter inference beats brute-force scaling.
Pre-optimized images lower the barrier to production inference. Teams often lack the GPU systems engineering expertise to tune vLLM configurations, select draft models, calibrate FP8 quantization, and configure paged attention. The Inference Optimized Image packages months of tuning into a deployment ready in as little as minutes, with production-grade performance accessible to teams focused on building applications, not becoming GPU infrastructure experts.
The Inference Optimized Image for GPU Droplets is available across H100, L40S, RTX 6000 ADA, and RTX4000 ADA GPU tiers. Whether you’re running a single model for conversational AI or deploying multiple models concurrently for a multi-agent system, the optimized image delivers production-grade performance out of the box.
To get started, visit the Droplets Features Page or talk to our team to discuss your inference workload requirements.
Benchmark methodology: All performance measurements were conducted using Llama 3.3 70B with the vLLM inference engine. Benchmarks cover three workload scenarios (512/512, 1024/512, 2048/1024 input/output token lengths) at concurrency levels 1, 2, 4, 8, and 16. The optimized configuration uses 2×H100 GPUs (TP=2) with speculative decoding, FP8 quantization, FlashAttention-3, and paged attention. The baseline uses 4×H100 GPUs (TP=4) with no optimization. Cost calculations are based on GPU hardware utilization costs and do not include additional infrastructure overhead or profit margins. Throughput and cost improvements diminish at concurrency levels above 16 and approach parity above 32 due to memory constraints at TP=2. Reported numbers are averages across all scenarios and concurrency levels unless otherwise noted.
About the author(s)
Related Articles

Load Balancing and Scaling LLM Serving
- April 15, 2026
- 7 min read

Building a Robust Documentation Agent with DigitalOcean Gradient AI Platform
- April 13, 2026
- 14 min read

Advanced Prompt Caching at Scale
- April 7, 2026
- 6 min read