By Adrien Payong and Shaoni Mukherjee

Introduction
Large language model-powered AI agents traditionally have one critical drawback: they have extremely limited memory. By default, an LLM can only remember what’s in the context window (chat history) or conversation. That means they quickly “forget” previously learned information at the end of a session or when they hit a token context limit, and are completely stateless across interactions. LangMem SDK addresses this limitation by introducing persistent long-term memory.
Agents powered with LangMem can learn and grow over time, remembering past interactions, key facts, preferences, and more across multiple sessions. In this article, we will cover what LangMem is, why long-term memory is useful, how LangMem works, and how to use LangMem in your own applications. We’ll explore performance and compare LangMem to other alternatives. By the end of this article, you’ll know how to use LangMem SDK to create “smarter” AI agents that have the memory they deserve.
Key TakeAways
- LangMem makes agents stateful: It transforms stateless, context-window–limited LLM agents into systems that retain knowledge across sessions.
- Multiple memory types are supported: LangMem handles semantic (facts), episodic (past interactions), and procedural (behavior rules) memory through a unified API.
- Memory management is LLM-driven: A Memory Manager analyzes conversations, decides what to store/update/delete, and consolidates knowledge over time.
- Storage is backend-agnostic: LangMem works with vector databases, key-value stores, Postgres, and other backends via a flexible store interface.
- Production readiness requires planning: Proper namespacing, pruning, retrieval optimization, and cost control are essential for scalable long-term memory systems.
What Is LangMem SDK?
LangMem SDK is an open-source software development kit (released by the LangChain team) that enables long-term memory for AI agents. In simple terms, LangMem SDK equips your AI agent with a long-term memory store, along with the mechanics to store, update, and retrieve knowledge from that store throughout the agent’s experiences with users. Paired with any language model and agent framework, LangMem can extract relevant information from conversations (or any other experience) and inject the appropriate memories into the agent context when necessary. LangMem SDK operates as a lightweight wrapper Python library, allowing it to integrate with any backend/memory store and agent framework.
With LangMem, an agent can remember facts or preferences, past occurrences, or even adapt to its own behavior based on feedback. Say you’re chatting with a virtual assistant and tell it your name or that you prefer something specific (“I like dark mode”). Using LangMem, the assistant can store that information in long-term memory. The agent can retrieve it later, even in a new conversation session, and reference that fact when generating a response (“Hello [Name], back again. I remember you like dark mode.”).
Under the hood, LangMem defines types of memories that an agent could potentially have. These memories include:
- Semantic memory – facts and data (e.g., important facts, user information, knowledge triples). Essentially, the agent’s expanding knowledge base of facts it has learned through interacting with users.
- Episodic memory - past experiences/events. Typically stored as episode summaries of past interactions (such as events that happened during a past conversation). This can be used to allow the agent to learn from specific past interactions/conversations.
- Procedural memory – learned behavior/instructions/policies that shape how the agent behaves (e.g., adapting its core “persona” or teaching it new rules that better suit its task). This can be used to adjust how your agent acts over time. LangMem provides a unified api you can use to work with any of the memory types. You specify what memories you would like your agent to use. LangMem will then extract that information from the conversation, store it, and recall it in future interactions.
Why Long-Term Memory Matters for AI Agents
By equipping agents with persistent memory, we enable several important capabilities:
- Continuous Context: A standard conversational agent can’t remember past interactions. With Long-Term Memory, agents can have an extended context for a conversation. You won’t need to re-feed the agent information from previous conversations. Imagine a customer support bot remembering a user’s last issue.
- Personalization: Agents can remember user preferences and profile info to tailor responses. If an AI tutor is aware of the topics a student struggled with last week, it can adjust its teaching approach accordingly.
- Learning from Experience: Memory allows agents to learn from their actions. By remembering past successes and failures, an autonomous agent can adjust its strategy. Agents with Memories aren’t “just simple, reactive tools. They can learn and adapt with use.”
- Task Continuity: The AI agent can remember information about the task it is performing. Let’s say it’s a programming agent that’s fixing bugs in your code. It may take several days to complete. If the agent has memory, it can remember the state of the task when it stops interacting with the user. If it didn’t have it, it would either need to rely on the user to recap progress or start from scratch.
- Reduced Prompt Size: Instead of cramming the entire conversation history into the prompt (which you’ll eventually hit context limits for and cause your application to become unnecessarily expensive), an agent with memory can fetch only the relevant information it needs from long-term storage. This allows you to be more efficient with the context window — the agent remembers what it needs rather than dragging.
Architecture and Technical Overview
LangMem’s architecture can be understood as a layered system that sits alongside the core agent logic:
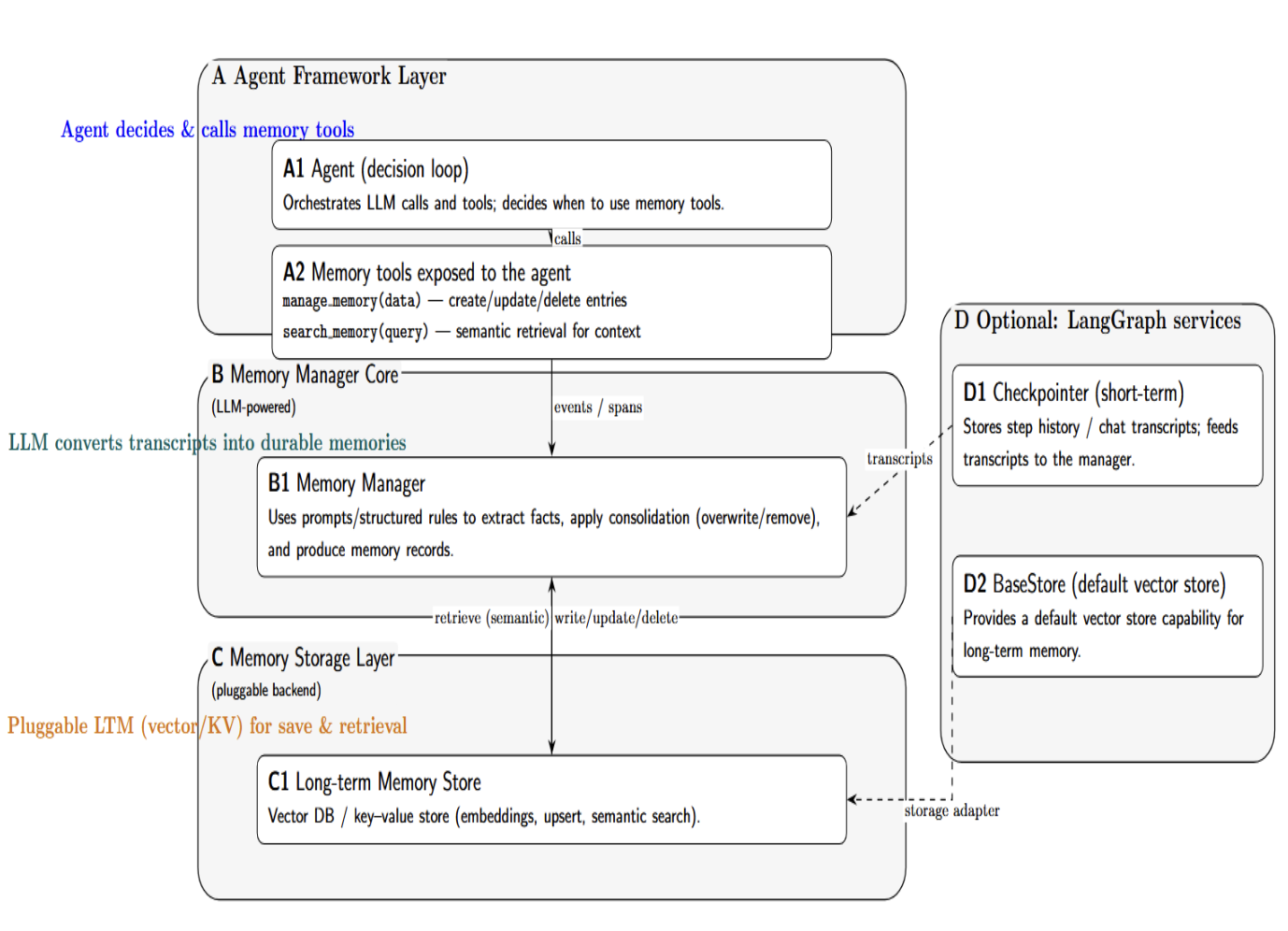
a. Agent Framework Layer: This is the agent (e.g., built with LangChain or your own framework) that interacts with the language model. The agent must be configured to use LangMem’s memory tools as part of its tool suite. For example, if you’re following LangChain’s framework recipe, you would create an agent and pass `manage_memory` and `search_memory` as tools to be called by the agent. The agent’s decision loop will then automatically incorporate these tools when necessary. Note that LangMem works with any agent framework. If you’re not using LangChain, you can simply call LangMem’s API within your own agent code.
b. Memory Manager Core (LLM-powered): The brain of LangMem is a Memory Manager component. This is effectively an LLM that takes conversation transcripts/data as input and produces memory entries as output. Under the hood, Prompt templates and structured instructions analyse the conversation transcript and determine what information to store/ update / delete. For example, if the last conversation added a new fact (“Bob is now heading the ML team”), then LangMem’s Memory Manager would understand (using an LLM like GPT-4 or Claude) and produce a corresponding memory record. The Memory Manager can also reason about existing memories – e.g., identify a fact about Bob in past memories that is now no longer true and should be overwritten/deleted (this is called consolidation logic).
c. Memory Storage Layer: LangMem doesn’t enforce any particular storage type but expects a memory store backend to actually store and retrieve memory entries. This will often be a vector database or any key-value store that can accept embeddings and allow for semantic search. You can think of this layer in the architecture as your long-term memory database. LangMem’s API only requires a store object with the correct interface (methods to save memory, query by embedding, etc.), so developers can plug in alternatives (e.g., Pinecone, Weaviate, Redis vector store) by writing a small adapter if needed.
d. LangGraph Integration (Optional): When integrating with LangChain’s LangGraph, you will also have access to Checkpointer and BaseStore services. These services provide checkpointing (short-term memory, i.e., logging of chat history) and BaseStores (which provide default vector store capability for LTM). LangMem SDK adds logic on top of these services – meaning the brain that determines what to put in the store or how to update it.
Data Flow Here’s a simplified view of how things work together when the agent is running:
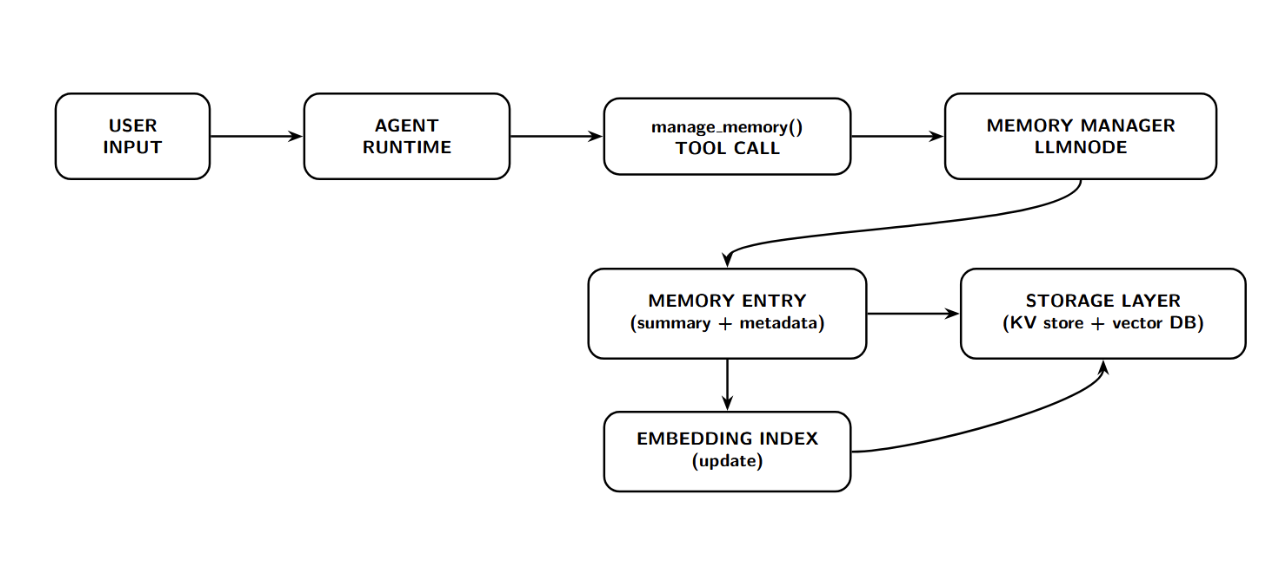
- a. During a conversation: The agent receives input from the user and processes it. As part of normal reasoning or tool use, the agent may choose to call the manage_memory tool, providing the current conversation content.
-
LangMem’s Memory Manager LLMNode will take that content, reason out what information is worth storing, and return a memory entry (or entries) to persist. That memory entry will be written to the storage layer (along with an embedding index used for retrieval later).
-
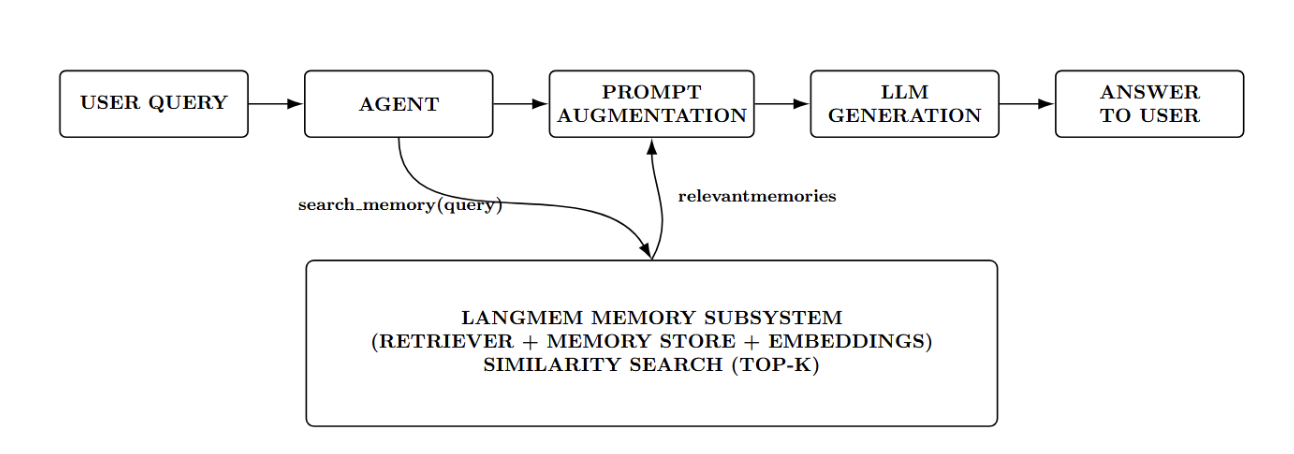
b. Later in the conversation or in a future session: when the agent receives a query or otherwise requires context, it may call the search_memory tool. LangMem will take a query (potentially the user’s question, or a topic), and perform a similarity search against memories in the memory store, returning any stored memories that are relevant.
-
The agent can then add those retrieved memory fragments to its prompt (typically appending to the system/user context) and have the LLM generate an answer using that information. This way, knowledge from past interactions is dynamically brought into the present conversation.
-
c. Background maintenance: Separately, a background thread/process (or scheduled job) may periodically invoke LangMem’s consolidation routine (assuming it’s enabled). This would operate on batches of memory entries (or perhaps the entire memory store), and, using the LLM-based Memory Manager, output cleaned-up memory - e.g., merging similar memories, summarizing old conversations, deleting flagged entries, etc. The output would then be written back to the store (overwriting/updating previous entries).
Integration Guide
Now we will go through how to use the LangMem SDK for your AI agent. We will be using Python for this example and leveraging LangChain’s utilities, but the process will be similar regardless of the language/tool used.
1) Python packages
You’ll need:
- langmem (memory tools)
- langchain (agent API)
- langgraph (stores + runtime wiring)
- provider packages (e.g., OpenAI)
Install:
pip install -U langmem langchain langgraph langchain-openai openai
If you plan to persist memory with Postgres later:
pip install -U "psycopg[binary,pool]"
2) Provider credentials
LangMem doesn’t include an LLM. You must configure a provider (e.g., OpenAI, Anthropic). For OpenAI:
export OPENAI_API_KEY="sk-..."
# You can set it before creating the agent:
import os, getpass
os.environ["OPENAI_API_KEY"] = getpass.getpass("Paste OPENAI_API_KEY: ").strip()
assert os.environ["OPENAI_API_KEY"], "Empty key."
Step 1 — Import the Updated Components
You will use create_agent from LangChain and a memory store from LangGraph:
from langchain.agents import create_agent
from langgraph.store.memory import InMemoryStore
from langmem import create_manage_memory_tool, create_search_memory_tool
In the above code:
- create_agent is the modern tool-using agent factory
- InMemoryStore represents the vector-backed store for long-term memories (for development/demo purposes)
- LangMem tools implement memory write/update + memory retrieval
Step 2 — Create a Memory Store (Demo Mode)
For development, start with an in-memory vector index:
store = InMemoryStore(
index={
"dims": 1536,
"embed": "openai:text-embedding-3-small",
}
)
What this means operationally:
- Each memory item is embedded into a 1536-dimensional vector.
- Semantic similarity search is used for retrieval.
- Memory will be reset when the process is restarted (perfectly okay for demos).
Step 3 — Define Memory Tools With User-Scoped Namespaces
Namespaces are by far the easiest/best mechanism to prevent memory leakage across users. Namespacing allows you to segregate memory entries when you have multiple agents or multiple users. This scopes the memories so that two agents or two users don’t mix knowledge with each other. If you’re building a system with multiple users, you could dynamically assign the namespace per user, like namespace=(user_id, “memories”). The LangMem tools will then only retrieve memories from the relevant namespace. The recommendation is to scope memory by a runtime user_id.
Memory write tool (manage memory)
manage_memory = create_manage_memory_tool(
namespace=("memories", "{user_id}"),
instructions=(
"Store stable user facts and preferences (name, role, long-running projects, UI preferences). "
"Avoid storing sensitive data unless the user explicitly requests it."
),
)
Memory read tool (search memory)
search_memory = create_search_memory_tool(
namespace=("memories", "{user_id}"),
instructions=(
"When questions depend on prior info (preferences, identity, previous tasks), search memory first "
"and use the results in the response."
),
)
Why this matters:
- (“memories”, “{user_id}”)tells LangMem you want to store memories in a per-user partition.
- When running, you pass the user_id in the agent call config, and LangMem fills the template.
Step 4 — Create the Agent
Now wire everything together:
agent = create_agent(
model="gpt-4o-mini", # choose your model
tools=[manage_memory, search_memory],
store=store,
)
At this point, you have:
- an agent driven by an LLM,
- tools that provide long-term memory writes/search,
- A store that semantically persists/retrieves memories.
As you can see, the LangMem integration is handled behind the scenes; there is no need to manually call any of the memory functions yourself. That’s the basic integration process. In just a few lines of code, we were able to add long-term memory to an AI agent.
Production Upgrade — Persistent Memory With Postgres
One detail to note would be making this memory truly long-term persistent through a persistent store. In our example, InMemoryStore would lose its data on restart. In a production app, you’d want to use something like:
from langgraph.store.postgres import PostgresStore
store = PostgresStore.from_conn_string("postgresql://user:password@host:5432/dbname")
store.setup() # run once
In this example, we use a Postgres database to persist memory. This is the agent’s knowledge even after the app has restarted. LangChain provides a PostgresStore to store text and embeddings in an SQL table. Of course, you could as easily point to any vector database here – if it’s wrapped in a store interface LangMem expects. The nice part is that once it’s persisted, the agent can effectively remember things indefinitely (or until you clean the database).
Performance & Scaling Considerations
Augmenting an agent with long-term memory significantly increases its capabilities. However, there are some new considerations around performance and scale that you should keep in mind. Here are some guidelines for working with LangMem:
| Consideration | Risk / Challenge | Practical Mitigations (LangMem-focused) |
|---|---|---|
| Memory Growth and Pruning | Over time, the agent accumulates many memory entries, which can slow retrieval and increase irrelevant recalls. | Apply pruning and compression policies: summarize older memories into fewer entries, keep only the most important facts (e.g., last 100), and use time-based decay for rarely referenced items unless marked permanent. Leverage LangMem’s background manager for periodic consolidation. |
| Retrieval Efficiency | Vector search latency can increase as the memory store grows to thousands+ entries, impacting responsiveness. | Use an indexed vector DB and monitor retrieval latency. Narrow searches via namespaces or sharding by memory type (e.g., “preferences” vs all memories). Tune top-k results and embedding model choice to balance precision vs speed. |
| Context Window Usage | Retrieved memories still consume tokens when injected into the prompt; large entries can push context limits and increase cost. | Store memories as concise, distilled facts instead of long transcripts. Summarize at write-time, extract key sentences, and set tool instructions to enforce brevity. Limit how many memories are injected per response. |
| Memory Scope and Privacy | In multi-user systems, unscoped memory can leak across users or include sensitive content that should not be stored. | Use user/tenant-scoped namespaces (and role/mode-specific namespaces if needed). Filter what is stored (avoid raw transcripts when unnecessary). Consider encryption at rest for sensitive content and enforce storage policies to keep only non-sensitive insights. |
| Scaling the LLM for Memory Operations | Memory extraction/consolidation quality and cost depend on the model; strong models cost more, weak models may produce low-quality memories. | Use model tiering: a smaller model for routine fact extraction, a larger model for periodic summarization. Control frequency (don’t extract on every turn unless notable), cache where appropriate, and track total LLM-call cost as usage scales. |
Comparison With Alternatives
Here’s a quick comparison of the main ways teams add long-term memory to AI agents. The table contrasts (1) building your own custom RAG-style memory layer from scratch, (2) integrating another memory-centric SDK into your stack, and (3) opting for LangMem’s all-in-one solution.
| Approach / Option | What It Looks Like in Practice | Key Trade-offs vs LangMem |
|---|---|---|
| Custom Memory Solutions (DIY RAG-style memory) | Building your own memory with a vector DB basically means: picking “important” messages, embedding them (say, with OpenAI), storing them in a vector database (say, Pinecone), retrieving the top matches at query time, and prepending them to the prompt. You also implement summarization/extraction prompts, update/delete logic, deduplication, and retention policies yourself. | Pros: Maximum control and flexibility for niche requirements; fully customizable pipelines and schemas. Cons: High engineering and prompt-engineering overhead; harder to maintain; easy to get inconsistent behavior; you must own pruning/consolidation/versioning. LangMem advantage: standardized, tested memory management pipeline that reduces plumbing and accelerates delivery. |
| Other Memory SDKs / Tools (e.g., Memobase and similar frameworks) | Use a dedicated memory toolkit/framework that provides user-centric memory and retrieval utilities; may include templates for memory schemas, storage backends, etc. Some orgs will also build their own memory modules internally. Most “AutoGPT-style” agent stacks will expect you to insert memory manually. | Pros: Potentially simpler if already aligned with your stack; may provide specialized UX for user memory. Cons: Feature coverage and maturity vary; may be tied to a specific service/backend; integration depth can differ. LangMem advantage: deep LangChain integration plus broader scope (tooling, background processing, multiple memory types, backend-agnostic design). |
| LangMem SDK (LangChain-first memory layer) | Tool-based memory write/search integrated into an agent loop, backed by a LangGraph store. Supports structured memory management and background consolidation, and is designed to work across storage backends. | Pros: Fast integration, consistent behavior, multiple memory types, storage flexibility, clean separation of memory logic from agent logic; reduces custom plumbing. Cons: Requires comfort with LangChain/LangGraph patterns; stateful systems add debugging/monitoring complexity (true for any long-term memory approach). |
FAQs
Does LangMem include its own language model? No, LangMem does not come with its own built-in language model. It acts as a memory layer that works alongside external LLM providers like OpenAI or Anthropic. You need to configure and connect your preferred model to use it effectively.
Can LangMem work without LangChain? Yes, LangMem is not strictly dependent on LangChain. While it integrates smoothly with LangChain-based workflows, it can also be used with custom-built agent systems. This makes it flexible for developers who want more control over their architecture.
Is memory automatically persistent? Memory is only persistent if you explicitly use a persistent storage backend like PostgreSQL or a vector database. If you use something like an in-memory store, the data will be lost once the session ends. So persistence depends on how you configure storage.
How does LangMem prevent memory leakage between users? LangMem uses namespaces to separate data between users or tenants. Each user’s memory is stored in an isolated scope, ensuring that information is not shared across sessions. This is important for both privacy and system reliability.
Does long-term memory increase costs? Yes, adding long-term memory can increase costs because it involves extra steps like storing, retrieving, and processing data. These steps may require additional LLM calls and storage resources. To manage costs, it’s important to prune unnecessary memory and optimize retrieval.
Conclusion
LangMem enables you to upgrade your stateless, context-window–bound LLM agents to stateful agents that retain user facts, preferences, and task history across interactions. It provides an LLM-driven memory manager along with an extensible storage layer and easy-to-use tooling (`manage_memory`, `search_memory`) for incorporating persistence into your applications. Forget trying to build a custom memory pipeline from scratch; with LangMem, you can have a fast path to production-ready persistent agent behavior. If you scope memory correctly (via namespaces), choose an appropriate store and plan for pruning and retrieval efficiency. LangMem can serve as a clean slate for building agents that learn and improve over time, while maintaining scalability and manageability.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
About the author(s)
I am a skilled AI consultant and technical writer with over four years of experience. I have a master’s degree in AI and have written innovative articles that provide developers and researchers with actionable insights. As a thought leader, I specialize in simplifying complex AI concepts through practical content, positioning myself as a trusted voice in the tech community.
With a strong background in data science and over six years of experience, I am passionate about creating in-depth content on technologies. Currently focused on AI, machine learning, and GPU computing, working on topics ranging from deep learning frameworks to optimizing GPU-based workloads.
Still looking for an answer?
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!
 This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
This work is licensed under a Creative Commons Attribution-NonCommercial- ShareAlike 4.0 International License.
Become a contributor for community
Get paid to write technical tutorials and select a tech-focused charity to receive a matching donation.

DigitalOcean Documentation
Full documentation for every DigitalOcean product.

Resources for startups and AI-native businesses
The Wave has everything you need to know about building a business, from raising funding to marketing your product.
The developer cloud
Scale up as you grow — whether you're running one virtual machine or ten thousand.

Start building today
From GPU-powered inference and Kubernetes to managed databases and storage, get everything you need to build, scale, and deploy intelligent applications.
